Sommario
Per full stack architecture si intende l’architettura scelta per realizzare un sistema informativo, generalmente di grandi dimensioni, dal database all’interfaccia utente.
Un’architettura software può essere definita di successo se ogni sua singola parte raggiunge efficacemente gli obiettivi per cui è stata pensata. L’efficacia del raggiungimento degli obietti è data dal giusto equilibrio tra prestazioni, flessibilità, possibilità evolutive, manutenibilità e costi realizzativi.
Ingegnerizzare un sistema informativo significa analizzare bene il dominio applicativo cui sarà dedicato e attuare molte scelte sulle tecnologie da utilizzare. Di particolare importanza saranno anche le scelte inerenti le modalità di lavoro del gruppo di progetto. Individuare interdipendenze e scadenze che non rallentino il lavoro dei sotto gruppi.
Devono essere evitate scelte dettate dalle mode correnti; non sempre le scelte largamente condivise rimangono tali. La moda dovrebbe infatti solamente suggerire alcune idee; si devono poi valutare con grande attenzione tutte le soluzioni ipotizzate per evitare di correre ai ripari solo successivamente.
Un progetto di successo passa anche dall’individuazione del fabbisogno formativo del personale: non sempre la scelta migliore è cercare un “esperto di…“. Spesso la soluzione migliore è formare il personale su nuove tecnologie; tale approccio presenta il duplice vantaggio di rafforzare la motivazione delle risorse e mantenere il loro know-how sempre aggiornato per necessità e non per scelta.
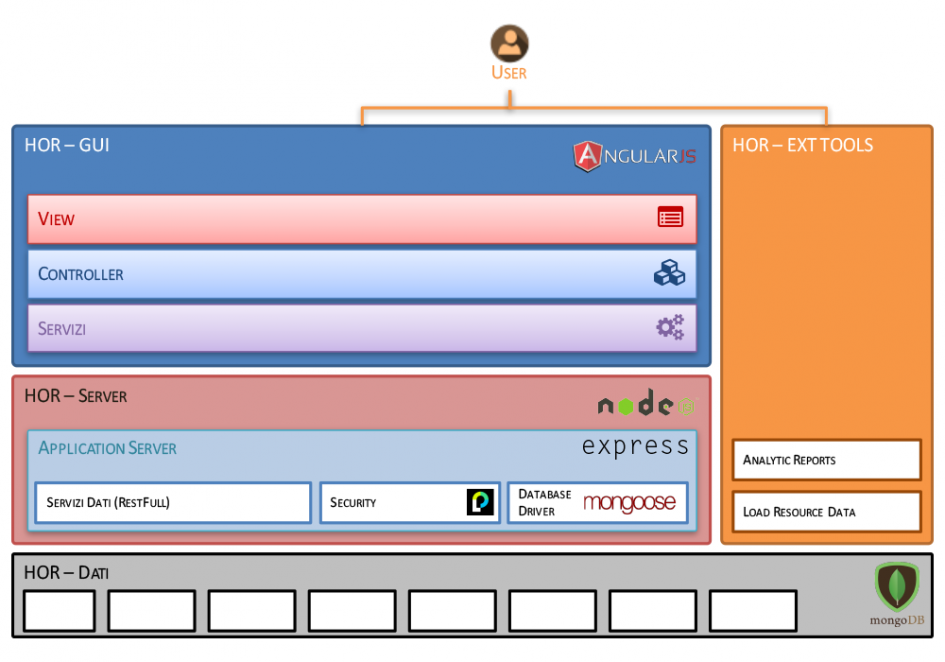
Progettare e realizzare una full stack architecture significa quindi analizzare i singoli fabbisogni del sistema e individuare le scelte tecnologiche migliori dalla memorizzazione dei dati alle interfacce utente.
Scelta del database
La scelta della tecnologia con cui realizzare il database è di particolare importanza ma, spesso, è una scelta obbligata; spesso, infatti, alcune parti del sistema sono già state realizzate e utilizzano funzionalità per la persistenza dei dati.
Tipologie
Un forte orientamento del passato e del presente è quello di approcciare la base dei dati come fosse un’estensione del blocco elaborativo ricorrendo agli ORM (Object Relational Mapping).
Questo è un tema complesso e ampio che merita ulteriori approfondimenti che saranno affrontati in altri aricoli. Qui mi limiterò a dire che è una strategia da valutare a fondo. Soprattutto rispetto all’affidabilità dei risultati ottenibili in termini di tempo sviluppo, manutenibilità e testabilità, rispetto a quelli ottenibili RDBMS (Relational Database Management System).
Le modalità di interazione con un RDBMS si basano sul ricorso a linguaggi più evoluti di quelli utilizzati per lo sviluppo, linguaggi orientati a quanto si vuole ottenere e non a come ottenerlo.
La base dei dati è spesso pensata per servire molteplici “pile applicative“. Si progettano pertantanto basi di dati atte a soddisfare obiettivi più ampi che non quelli specifici della singola applicazione. Gli ORM hanno invece la tendenza a modellare la base dei dati secondo le necessità di chi li sta utilizzando, limitando così fortemente le possibilità di disegno dei dati.
SQL e NO SQL

In questi ultimi anni si è aperto un grande confronto tra i sostenitori dei database i cui dati sono definibili ed interrogabili con il tradizionale SQL, come Oracle e MySQL, e i sostenitori dei database con un approccio NOSQL come MongoDB.
Questo però è un capitolo molto ampio e complesso e richiede un approfondimento specifico. Certamente hanno provocato una profonda spaccatura nel mondo delle scelte tecnologiche. Anche se vale la pena ricordare che il grado di maturità e affermazione dei sistemi basati su SQL è comunque una garanzia per i sistemi di ampie dimensioni.
Inoltre, attualmente anche nei sistemi SQL hanno adottato alcune delle tecniche NOSQL offrendo una grande varietà di possibilità per accogliere in modo efficace e completo le tante nuove esigenze dettate dallo sviluppo del software.
Cluster applicativi
Nicolaus Wirth, in Algorithms + Data Structures = Programs, evidenziava quale fosse la grande importanza di pensare allo sviluppo in modo integrato algoritmi e strutture dati. Attualmente i “programmi” diventano cluster applicativi complessi costretti a confrontarsi con la continua esigenza di far evolvere i servizi offerti e mantenere prestazioni accettabili.
In un ambito professionale avanzato sono da prediligere soluzioni tecnologicamente mature ed affidabili. L’uso di queste tecnologie può puoi essere gestito come meglio si ritiene, anche mescolando gli approcci. È importante lasciarsi sempre la possibilità di poter gestire i dati anche esternamente ai sistemi con procedure consolidate e sicure come quelle offerte dagli RDBMS.
Il server
Si colloca nella zona centrale della full stack architecture: si interfaccia con i dati e offre i suoi servizi al client.
La tecnologia RESTful
Dare una definizione di server può risultare limitativo e fuorviante. Sono infatti cambiate profondamente le modalità di “pensare” un server ed oggi si predilige pensarvi quale cluster di servizi, preferibilmente stateless.
Impostare un’architettura basandola su servizi che non prevedano la gestione dello stato applicativo significa pensare ad applicazioni basate su singoli servizi “atomici”.
La suddivisione degli incarichi nella progettazione, nello sviluppo e nel test, diventa molto più semplice e gestibile. Si guadagna la possibilità di distribuire il carico di lavoro su più macchine e accedere, in modo trasparente, a servizi di varia natura e collocazione anche presso terzi.
RESTful (riposante) è quindi il concetto che sintetizza il nuovo approccio seguito nella realizzazione di server che offrono un’interfaccia semplice e sicura. È sufficiente prevedere l’inserimento di uno strato preliminare e automatico di verifica dell’autenticità e abilitazione del processo client, mediante token.
Per ogni entità trattata si realizzano almeno i cinque servizi base (Creation, Read, Update, Delete and List) e tutte assoggettate al controllo del token.
Tale approccio ha anche semplificato enormemente la realizzazione di sistemi “Single Sign On“: un servizio di autenticazione (anche google o facebook) “garantisce” l’utenza mediante generazione di token abilitativi accoppiati successivamente a token applicativi. L’utente, una volta autenticato, può quindi interagire con vari servizi offerti anche da realtà differenti.
Le prestazioni
La suddivisione delle funzionalità del server in tanti micro servizi e l’adozione di nuove tecnologie mirate alla gestione asincrona di microblocchi funzionali, ha consentito un forte avanzamento sul fronte delle prestazioni. Non più processi pesanti e monolitici ma tanti micro processi asincroni incaricati di gestire loro il richiamo del processo principale a lavoro ultimato.
Questo approccio consente di distribuire agevolmente più servizi su più hardware e gestire i carichi di lavoro in modo agevole e flessibile.
La tecnologia più utilizzata attualmente in tale ambito è NodeJs. Giunto oramai a versioni molto avanzate, garantisce una grande flessibilità nell’uso e un’alta integrabilità con framework importanti e di larghissimo uso come Express JS che offronto molteplici funzionalità avanzate per la gestione via HTTP dei servizi.
Interfaccia utente
Dalla compilazione di client più o meno voluminosi e la loro installazione presso gli utente si è passati alla distribuzione online di applicazioni che eseguite dal browser.
Ancora oggi però si può scegliere un’architettura più tradizionale dove le pagine vengono preventivamente preparate sul server (come con php, jsp, asp) e scaricate sul browser. Questo sistema ha però il limite di delegare il carico di lavoro prevalentemente sul server.
Si è allora ricorsi ad uno sviluppo intensivo di sistemi basati su javascript (jQuery, Angular, React), ovvero applicazioni eseguite interamente sul browser ma in costante collegamento con servizi vari, ubicati su più server, se necessario.
Javascript, all’inizio snobbato perché più involuto di altri linguaggio, oggi annovera molteplici versioni e subset (come Typescript) object oriented e quindi dotate di tipizzazione.
Javascript e JSON
Sviluppare oggi in javascript, o in una delle sue evoluzioni, garantisce il supporto di editor evoluti e una manutenibilità al pari, se non superiore, alle tecnologie di un tempo.
Grazie a questo nuovo approccio, le informazioni tra loro correlate appaiono contemporaneamente a video aggiornandosi costanemente mentre l’utente modifica i dati. Le interfacce utente diventano molto più veloci e intuitive, dando all’utente informazioni immediate ed aggiornate.
Il nuovo approccio sposta l’esecuzione degli algoritmi correlati alle azioni dell’utente sui client. Il server fornisce i dati, prelevati dai database ed elaborandoli quanto basta per renderli disponibili all’interfaccia.

Le strutture dati possono evolvere durante l’esecuzione anche nella loro forma definendo tecniche di “dynamic shaping” dei dati. A tal fine vengono molto utilizzate le definizioni JSON che associano alla definizione del dato il suo popolamento.
Javascript prevede nativamente il ricorso ad una forma evoluta di JSON per la descrizione dei dati che viene ripresa in Typescript per la definizione di Oggetti e Interfacce.
Risulta pertanto spontaneo ricorrere sempre più a linguaggi che tendano a semplificare la descrizione, oltre che il popolamento, delle strutture dati.
Da jQuery ad Angular o React
Da una prima fase in cui sono stati realizzati degli “inserti” di codice scritto in javascript per migliorare gli aspetti dinamici delle interfacce affidandosi a tencologie come jQuery, si è passati a tecnologie come Angular o React.
Questo nuovo approccio ingegnerizza sistematicamente le interfacce basandole sulla netta distinzione tra HTML e Javascript supportando soluzioni orientate agli oggetti.
Ogni “vista” è un componente che prevede una parte di codice, che ne descrive il funzionamento, e una parte HTML che ne descrive l’aspetto grafico.
Un vecchio sogno inseguito per decenni, quello della separazione tra grafica e codice, ricorrendo a varie soluzioni evolutesi costantemente nel tempo.
Quella di oggi sempre però una soluzione destinata a permanere nel tempo proprio per il suo approccio pulito e altamente manutenibile.
Tecnologie trasversali alla full stack architecture
Grazie all’introduzione di tecnologie e linguaggi sempre più evoluti e sempre più omoegenei nell’approvvio, sui è arrivati ad un’omogeneizzazione delle soluzioni, potendo usare Javascript, o Typescript, sia a livello server che a livello di interfaccia utente.
Un unico know-how evoluto e consolidato con tantissime librerire e framework già pronti e facilmente personalizzabili.
Si è infatti aperta un’era in cui è possibile sviluppare intere pile applicative, a partire dalla base dei dati sino all’interfaccia utente utilizzando pressoché sempre lo stesso linguaggio, lo stesso editor, gli stessi sistemi di test e debugging.
Non si tratta di una grande rivoluzione ma di tanti piccoli avanzamenti che anno dopo anno hanno portato ad uno stadio di avanzamento molto efficace sia per l’efficacia che per la qualità dei sistemi informatici.
Open Source: il vero riuso del software
Alla fine degli anni ’90 in tutte le aziende di produzione del software si parlava del riuso come della strategia centrale per risparmiare in termini di ore di sviluppo e test.
Ogni azienda costruiva il proprio catalogo di oggetti e librerie perfettamente funzionanti ma sempre “cablati” nella filosofia aziendale corrente. Al punto che progetti della stessa azienda ma operanti in ambiti diversi facevano comunque fatica a riutilizzare il software condiviso.
Questa è l’era dell’Open Source dove tutti condividono software e documentazione.
Lascia un commento